はじめに
Stable Diffusionでimage2imageをやってみた記録です。
前回のStable Diffusionの記事ではテキストのみの指示だったんですが、今回は画像とテキスで画像を作らせるimage2imageをやってみました。
具体的には、元になる画像を用意して、画像を処理する指示(テキスト)を打ち込むと、AIが新しい画像を作ってくれるという内容です。
色々試したところ、こんな感じで2D(左)のフクロウを3D化(右)することができました。

これ、実はパジ(@paji_a)さんがやっている「dMoonbirdsNFT」のマネです。
「dMoonbirdsNFT」はMoonbirdsという海外で有名なジェネラティブNFTをStable Diffusionで3D化するNFT企画。
パジさんはもっと素晴らしい3Dキャラを生み出していますよ。
1/ 今日は世界に広げるAI活用ジェネラティブ『dMoonbirdsNFT🦉』の実験企画を紹介します。昨夜締切したホワイトリスト募集に1,988名の方が応募いただきました。実験にご協力いただいている心優しき方いつもありがとうございます。「オリジナル」と「AI発3Dキャラ」お楽しみください。CC0で活用自由です pic.twitter.com/F9XYRCtDg2
— ⚔️paji.eth⚔️ (@paji_a) September 7, 2022
私もこんな作品を作ってみたいな、この技術を触ってみたいなって思ってたんです。
で、Stable Diffusionのimage2imageにチャレンジした次第ですが、初めはなかなかうまくいきませんでした。
何度も試すうちにコツを掴んで、この可愛いフクロウさんが出てきたといった感じです。
この記事では、Stable Diffusionでimage2imageを実行する環境をPCで作るための手順をまとめました。
プログラミング素人の私でも、見よう見まねでできたので、Stable Diffusionが気になっている人が始めるきっかけになればと思います。
Stable Diffusionのような技術が画像分野以外に横展開していくと、世界が変わってしまうかもですね。
すごいものが出てきました。
なお、Stable Diffustionを触るためにHugging FaceとGoogle Colabを使っています。
Hugging FaceとGoogle Colabの基本的な設定はこちらの記事で紹介しているので、まだの人は参考にしてくださいね。

参考サイト:Google Colab で はじめる Stable Diffusion v1.4 (2) – img2img
今回の試みで参考させて頂いたのはnpakaさんの記事です。
npakaさんはたくさんの書籍も出されているプログラマー。
わかりやすいStable Diffsionの記事だったので参考にさせていただきました。
Google ColabでStable Diffusion をインストールする
はじめに、Google Colabにアクセスして「ファイル」→「ノートブックの新規作成」をクリックします。

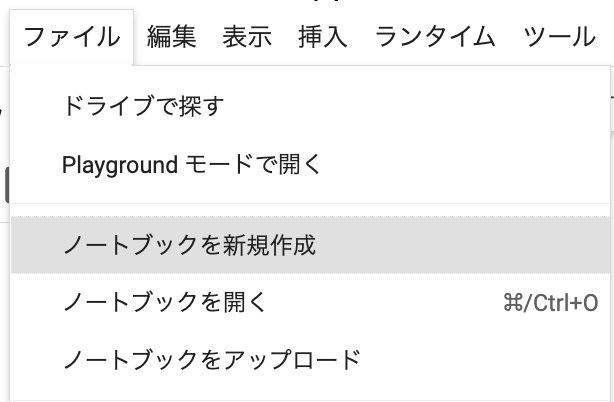
続いて「編集」→「ノートブックの編集」をクリック。
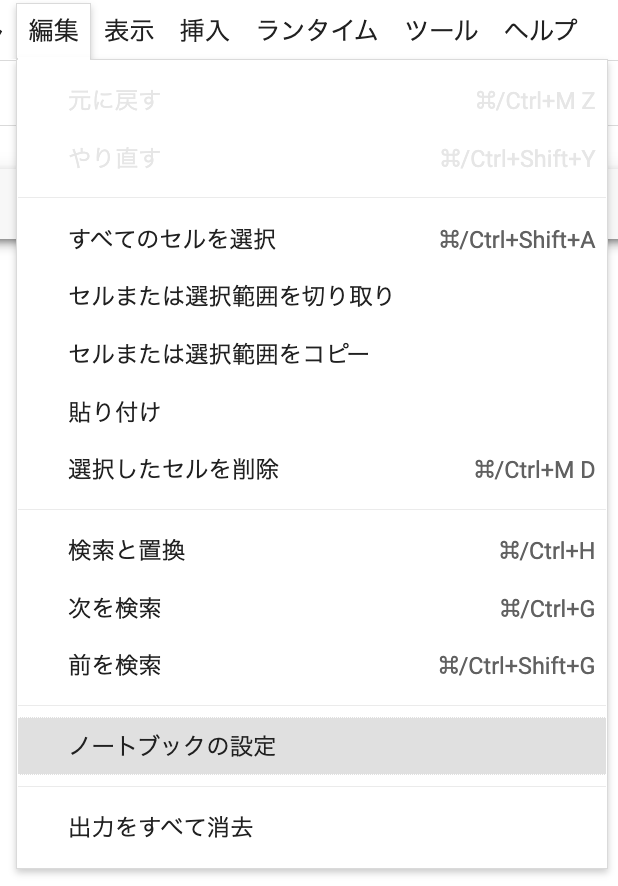
ハードウェアアクセラレータで「GPU」を選択して「保存」をクリック。
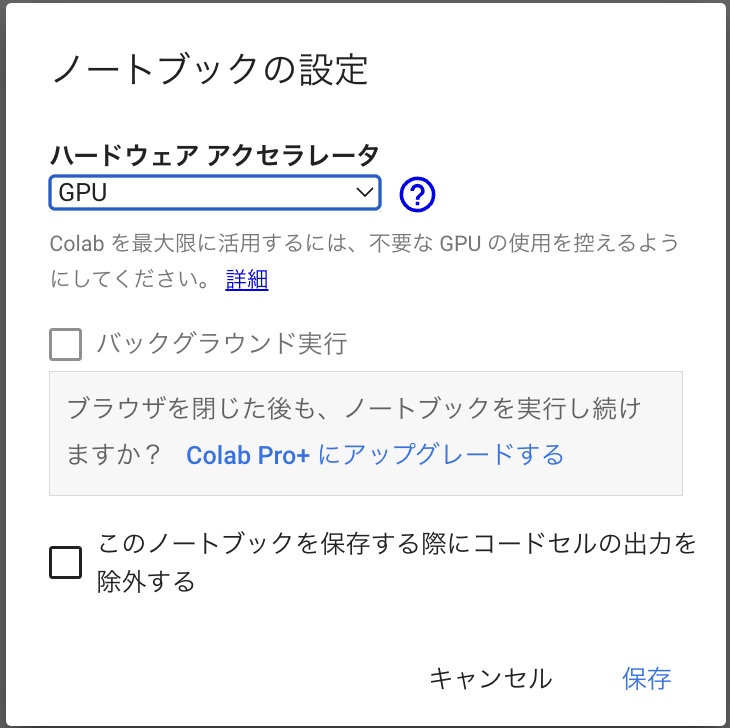
ここからimage2imageをできるようにStable Diffsionをインストールしていきます。
まずこちらのコマンドを入力して実行します。
!pip install transformers scipy ftfy
!pip install git+https://github.com/huggingface/diffusers.git

続いて「+ コード」をクリックしてコードセルを追加。

以下のコマンドの「HugginFace Hubのトークン」部分にHugginFaceで入手したトークンをコピペします。
(詳細はこちらの記事の中で紹介しています)
YOUR_TOKEN=“HugginFace Hubのトークン”

続いて以下のコマンドを実行。
import torch
from diffusers import StableDiffusionImg2ImgPipeline
# StableDiffusionImg2Imgパイプラインの準備
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
“CompVis/stable-diffusion-v1-4”,
revision=“fp16”,
torch_dtype=torch.float16,
use_auth_token=YOUR_TOKEN
).to(“cuda”)
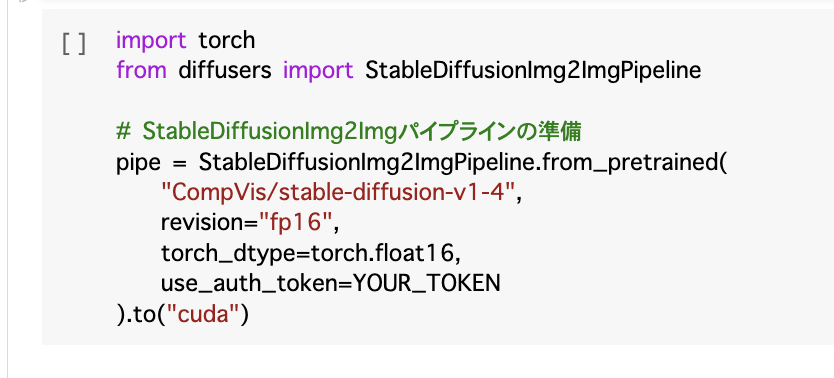
ズラズラっと処理が開始されるので、数分かかります。
無事に終わったらStable Diffusionのインストールが完了です。
Stable Diffusionでimage2image
ここから実際にimage2imageで画像を作っていきます。
まず元となる画像(今回は猫)を「imput.png」という名前で「Content」フォルダの直下にアップロード。
画像のアップロードはGoogle Colabの左側メニューからフォルダアイコン→「content」→「アップロード」でファイルを選んでください。
次にこちらのコードを実行すると画像を「output.pnp」として作成してくれます。
from PIL import Image
from torch import autocast
# 画像生成
prompt = “cat of ukiyoe style”
init_image = Image.open(“input.png”).convert(“RGB”)
init_image = init_image.resize((512, 512))
with autocast(“cuda”):
images = pipe(
prompt=prompt, # プロンプト
init_image=init_image, # 入力画像
strength=0.75, # 入力画像と出力画像と相違度 (0.0〜1.0)
guidance_scale=7.5, # プロンプトと出力画像の類似度 (0〜20)
num_inference_steps=50, # 画像生成に費やすステップ数
generator=None, # 乱数シードジェネレータ
)[“sample”]
images[0].save(“output.png”)

ポイントは、promptの“cat of ukiyoe style”、strength、gauidance_scale、num_inference_step、generatorのパラメータ。
数値をいじるとちょっとずつ出てくる画像が変わります。
作成された「output.png」はcontentフォルダの直下に保存され、「output.png」をダブルクリックすると、右側に画像が表示されます。
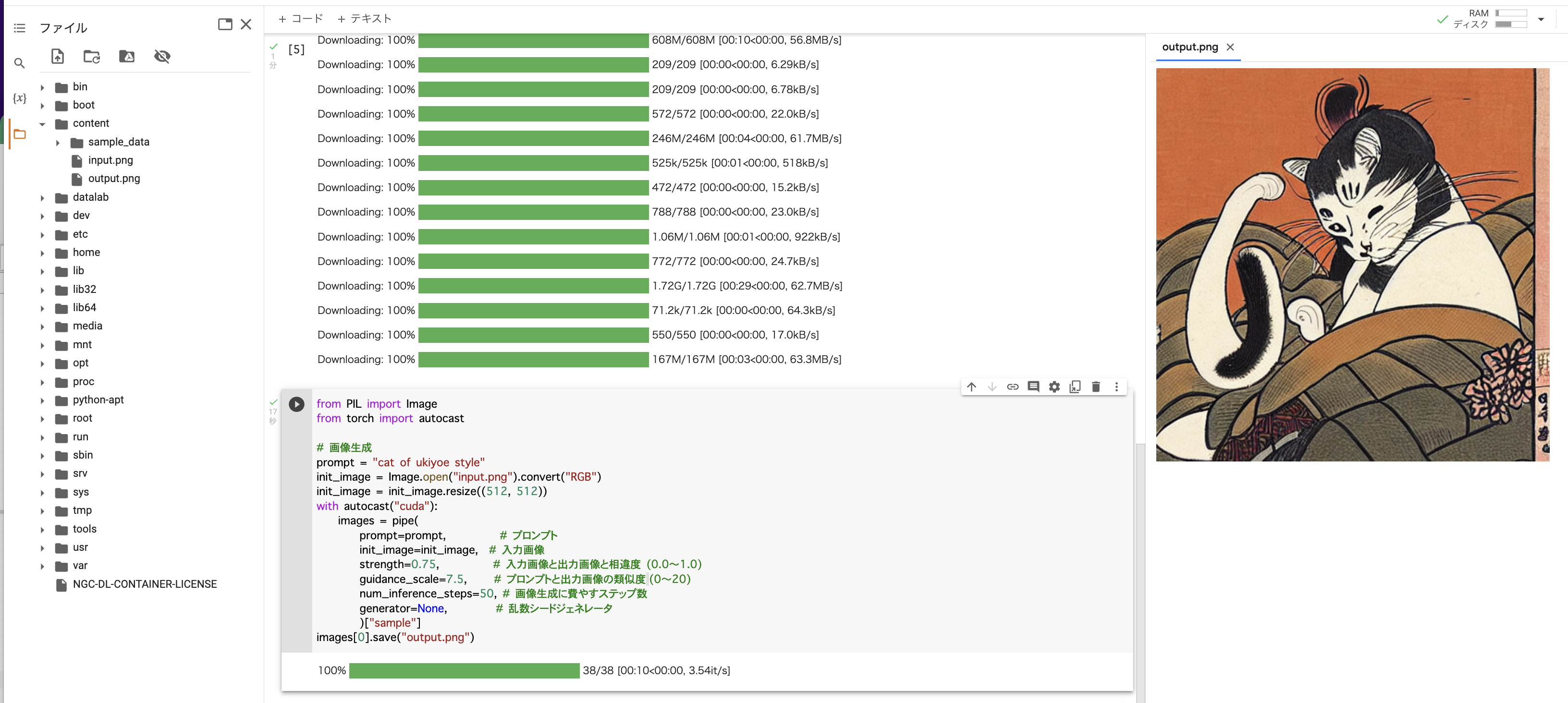
猫の浮世絵風の猫が出てきました。
で、このコードを参考にして、2Dの画像を3D化するという実験を行いました。
個人的に上手くいったなと思うのは、Moonbirdsの#1375の3D化です。
CC0のMoonbirdsの画像を用意して、Google Colabにアップロードしておきます。
次に上のコードの数値を変えていろいろ試したところ可愛いフクロウが出てきました。
パジさん(@paji_a)のマネしてStable Diffusionで Moonbirds(#1375)を3D化してみました。
ここまでくるのに時間がかかってしまった。
まずは触れてみるところから。#stablediffusion #Moonbirds pic.twitter.com/aqv2jsKrwh
— アールグレイ@仮想通貨ブロガー🐻👉🐼👈🐻❄️ (@earl_grey_y) September 7, 2022
CC0 とは、科学者や教育関係者、アーティスト、その他の著作権保護コンテンツの作者・所有者が、著作権による利益を放棄し、作品を完全にパブリック・ドメインに置くことを可能にするものです。CC0によって、他の人たちは、著作権による制限を受けないで、自由に、作品に機能を追加し、拡張し、再利用することができるようになります。
最後に
image2imageができる環境を作るのって難しいのかなと思ったんですが、参考人にさせていただいたコードを使うことで簡単にセッティングできることがわかりました。
また、image2imageで2D画像を3Dに化するところは簡単にできたんですが、希望していたようなイメージのフクロウを出すことが難しいというのも実感。
数値をいじりすぎるとフクロウからかけ離れた画像が出てしまうんですよね。
まだテキストで指示を出す出すところはまだよくわかっていないので、いろいろStable Duffsionの呪文を勉強したいと思います。
関連記事








おすすめ記事
