はじめに
この記事では、『Whisper』を使って音声ファイルから文字起こしする方法を解説します。
『Whisper』はOpenAIが提供している無料の文字起こしサービスとして公開している音声認識モデルです。
680,000時間分の多言語・マルチタスクのデータを使用した自動音声認識(ASR)システムで、大規模で多様なデータセットを使用することで、アクセント、バックグラウンドノイズ、専門用語への対応が向上しています。
多言語の文字起こしや、言語間の翻訳を可能にしています。
この記事で紹介する『Whisper』を使った文字起こしの流れはこのような形です。
- 「BackgroudMusic」と「QuickTime Player」で音源を録音して音声ファイルを作成
- 「Google Colaboratory」上で『Whisper』を実行して、音声ファイルを『Whisper』に読み込ませて文字起こし

「BackgroudMusic」と「QuickTime Player」で音声ファイルを準備する
まず、文字起こししたい音源を決めておきます。
なお、再生しながらマイクで音声を拾う録音のやり方だと周りの環境の音が雑音として入るのが厄介ですよね。
「BackgroundMusic」を使えば、Macのスピーカーの「音データ」を直接マイクに流すことができます。
スピーカーから外に出た音を録音するやり方ではないので、元の音源の状況をそのまま綺麗に録音することができるんです。
「BackgroundMusic」はこちらかダウンロードしてください。

ダウンロードページの下の方に「Download」の項目があり、「BackgraoundMusic-0.4.0.pkg」をダウンロードしてインストールします。
(私の環境MacBookPro M1 Max、macOS 13.1で利用できています)
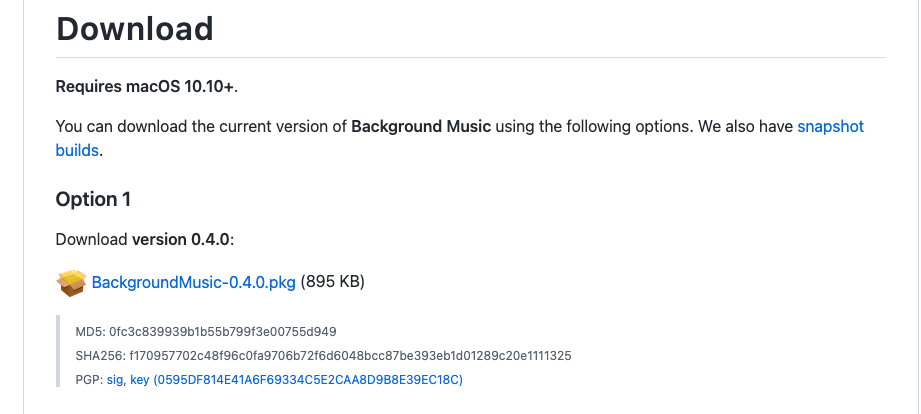
インストールが終わったら、サウンドの出力設定です。
Macの「システム環境設定」から「サウンド」を選んで、出力で「BackgroundMusic」を選択しておきます。
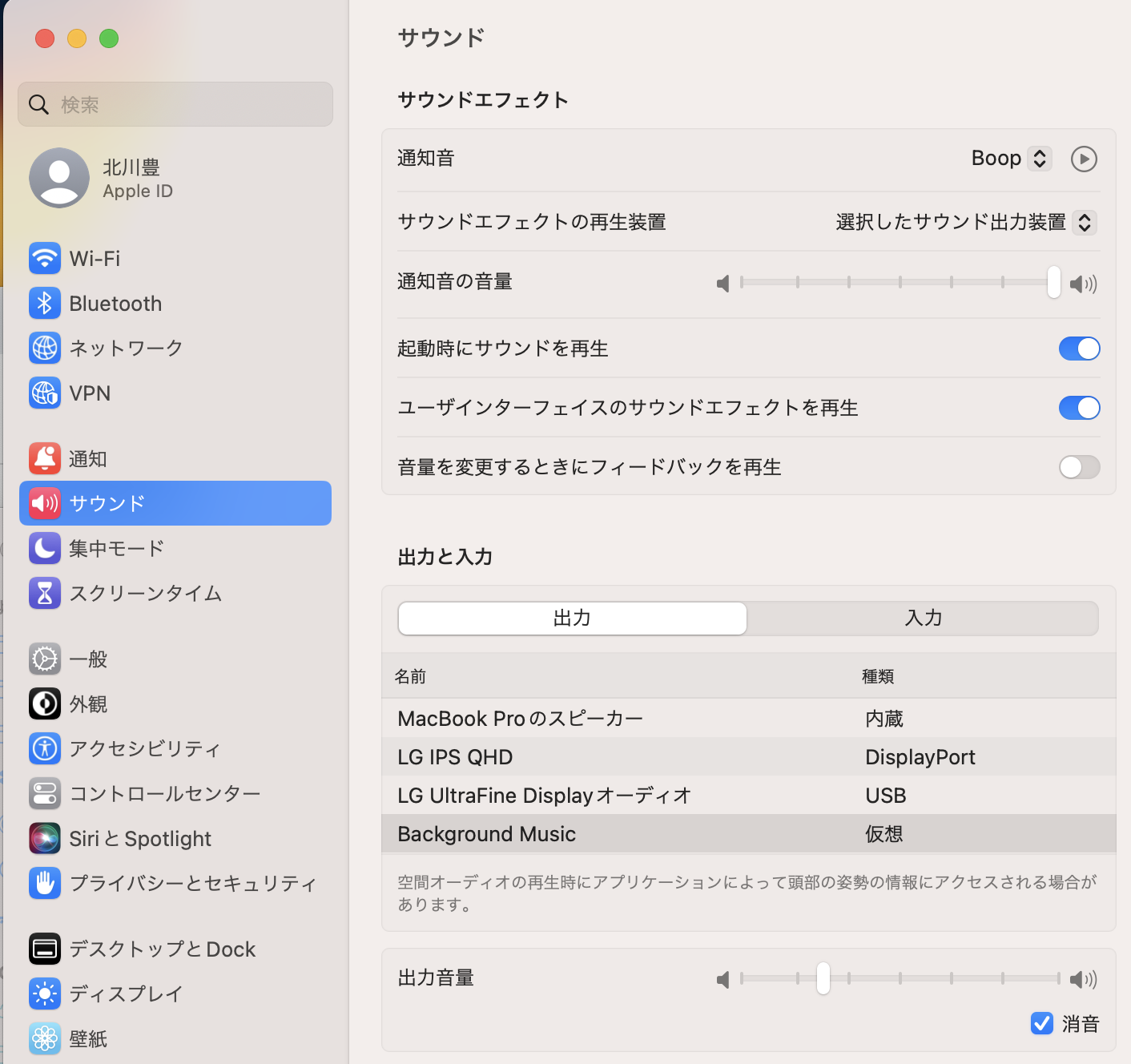
セッティングしたら、Output DeviceがMacの任意のデバイス(今回はスピーカー)を選択します。
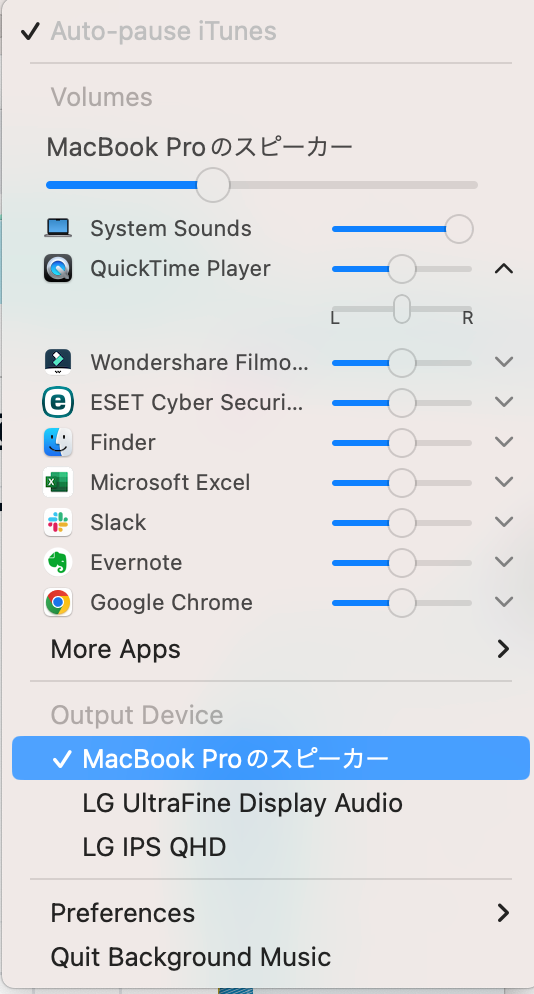
次に音源を録音する「QuickTime Player」を立ち上げます。

「ファイル」の「新規オーディを収録」を選択。
オーディオ収録の真ん中にある録音ボタン(赤丸ボタン)をクリックして録音を始めます。
続いて、録音したい音源を再生します。
「音データ」は直接マイクに流れているので、再生成中はスピーカーの出力をゼロにしてもちゃんと録音してくれますよ。

録音を終了する際はQuickTime Playerの停止ボタン(四角ボタン)をクリックします。
停止すると再生できるようになるので、録音した音声ファイルを確認してください。
録音を確認できていたら名前をつけて保存をします。
これで『Whisper』に取り込ませる音声データの準備ができました。

音声データのファイル形式は「m4a」のままで大丈夫です。
「Google Colaboratory」上で『Whisper』を実行して、文字起こしする
続いて、「Google Colaboratory」上で『Whisper』を呼び出します。
「Google Colaboratory」はGoogleのアカウントを持っている人が無料で使えて、機械学習の教育及び研究用に提供しているインストール不要で、すぐにPythonや機械学習・深層学習の環境を整えることが出来る無料のGoogleが提供するサービスです。
「Google Colaboratory」を使うと、CPU及びGPU(1回12時間)分の環境が利用可能になります。
「Google Colaboratory」は有料版も用意されていて、もし長時間利用する場合は検討の余地ありです。
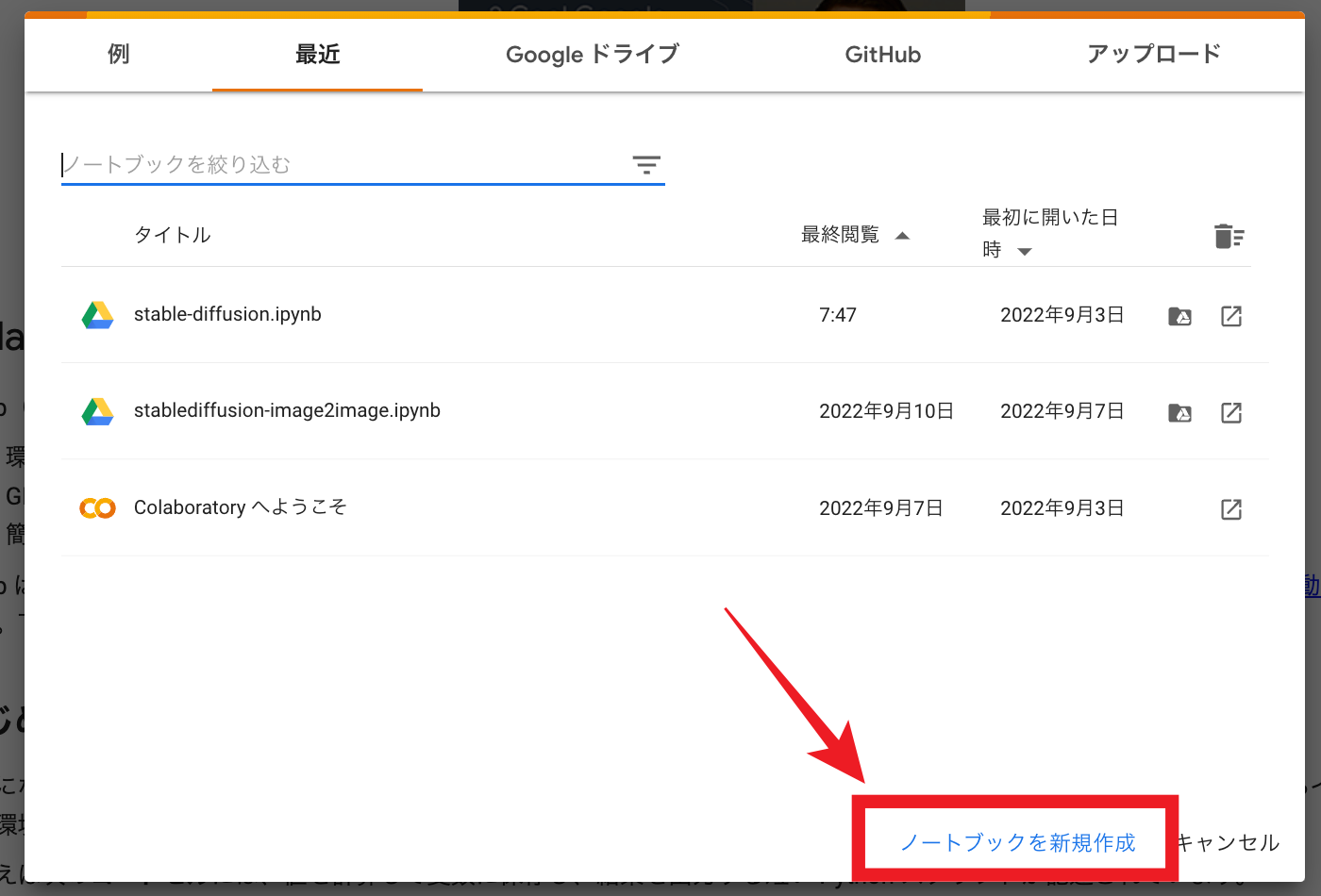
ここから「Google Colaboratory」を呼び出したら、一番下の「ノートブックを新規作成」をクリック。
続いて「接続」をクリック。
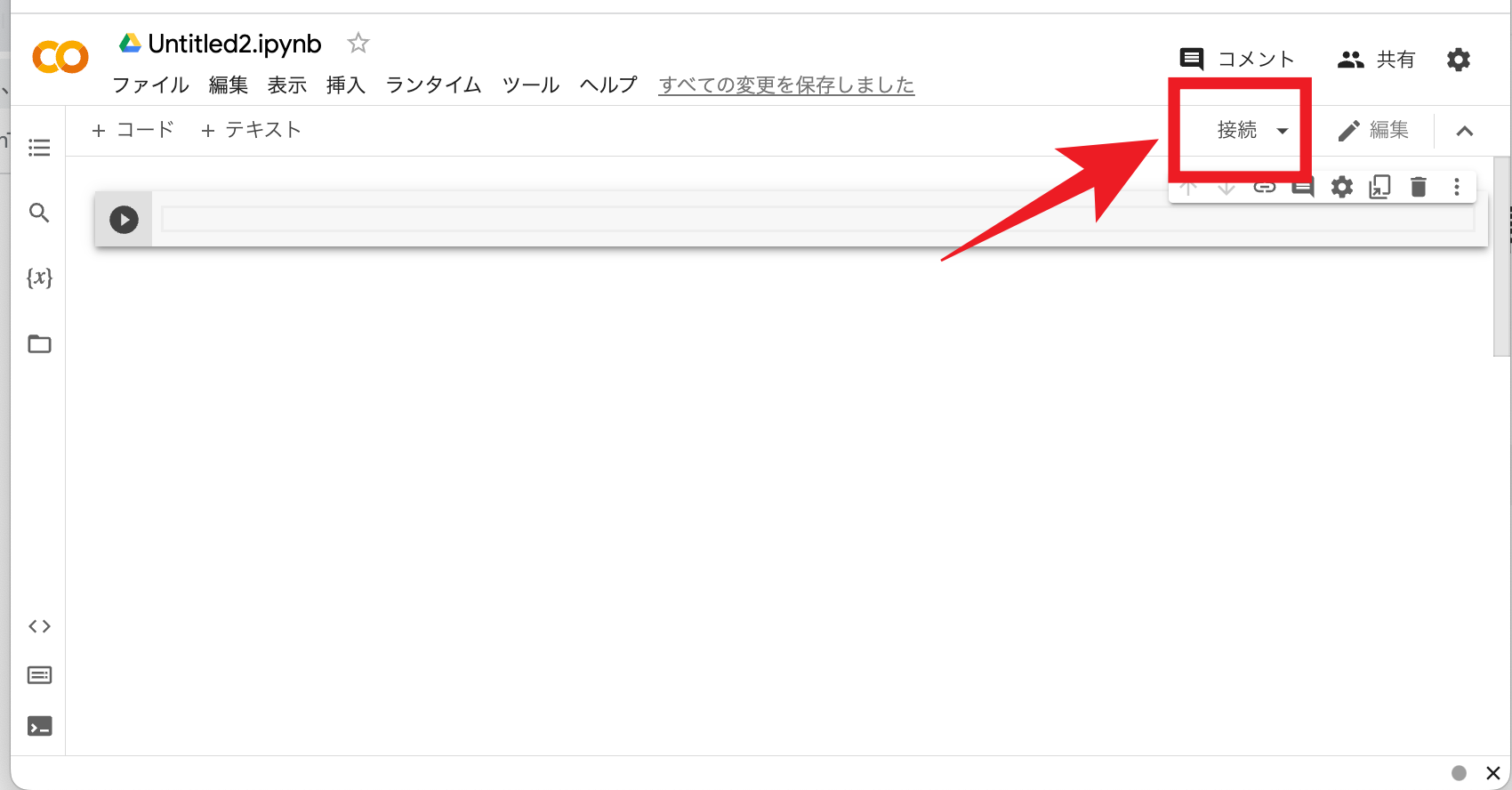
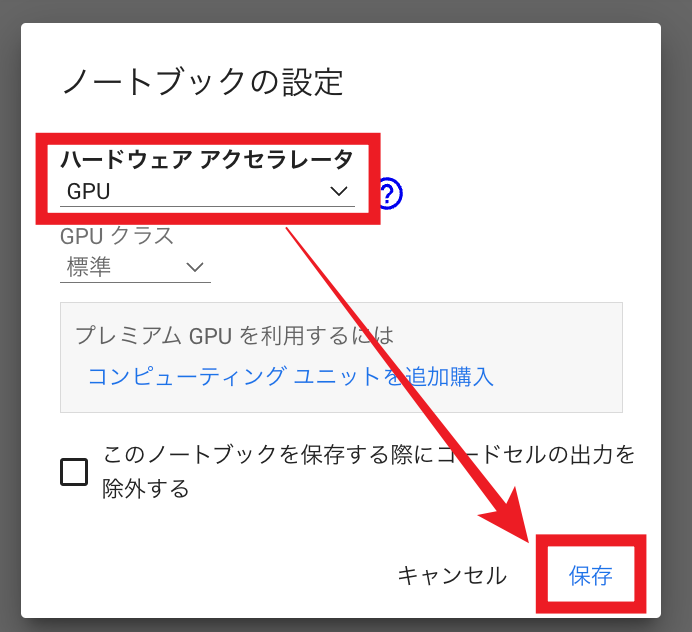
次に「編集」から「ノートブックの設定」をクリック。
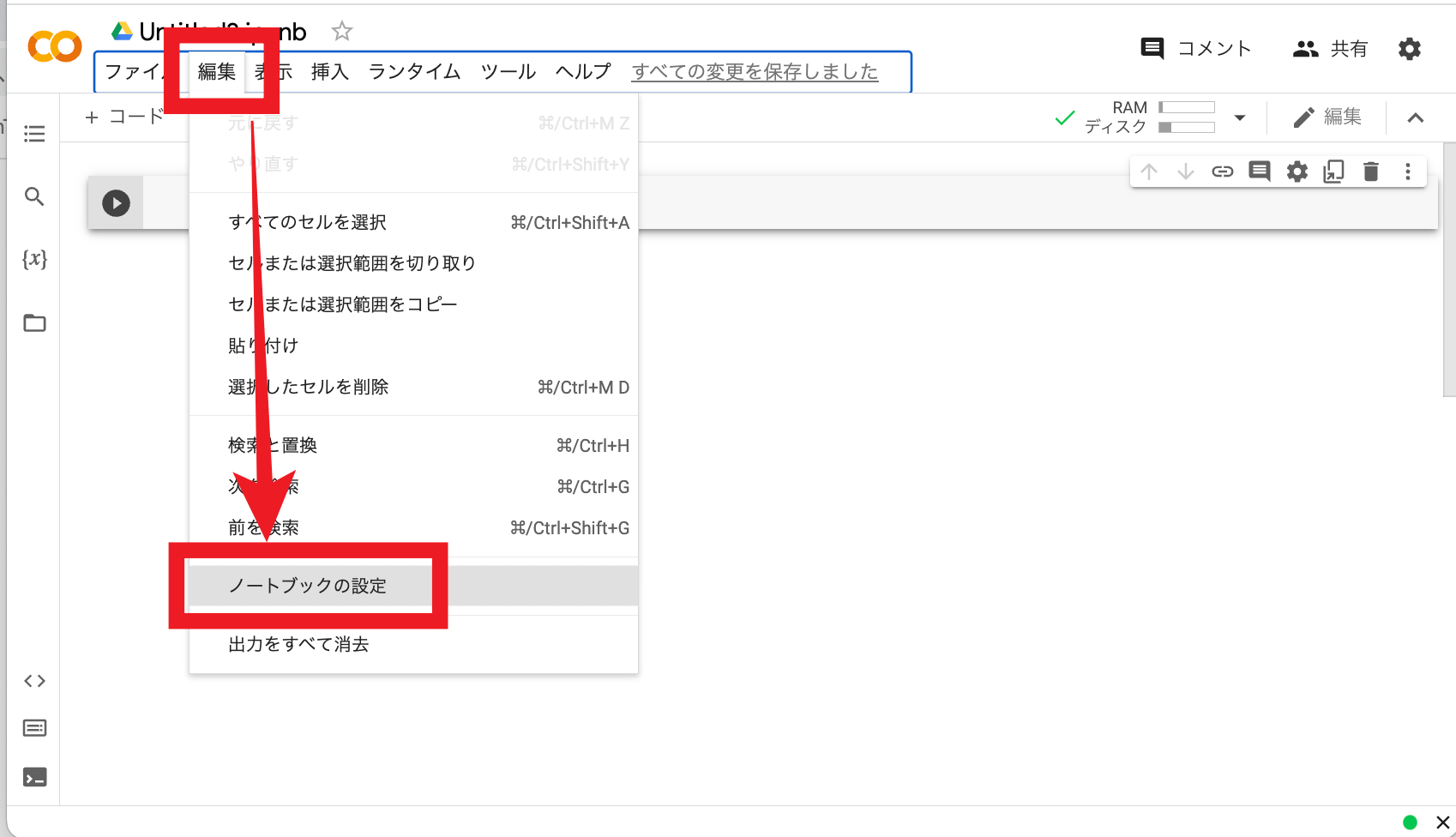
ハードウェア アクセラレータに「GPU」を選択して「保存」をクリック。
ここからコマンドを実際に入力していきます。
コマンドはコピペでOKです。
まず、以下のコマンドを入力エリアにコピペして、実行ボタンをクリックしてください。
!pip install git+https://github.com/openai/whisper.git

ズラズラと文字が流れて『Whisper』がインストールされます。
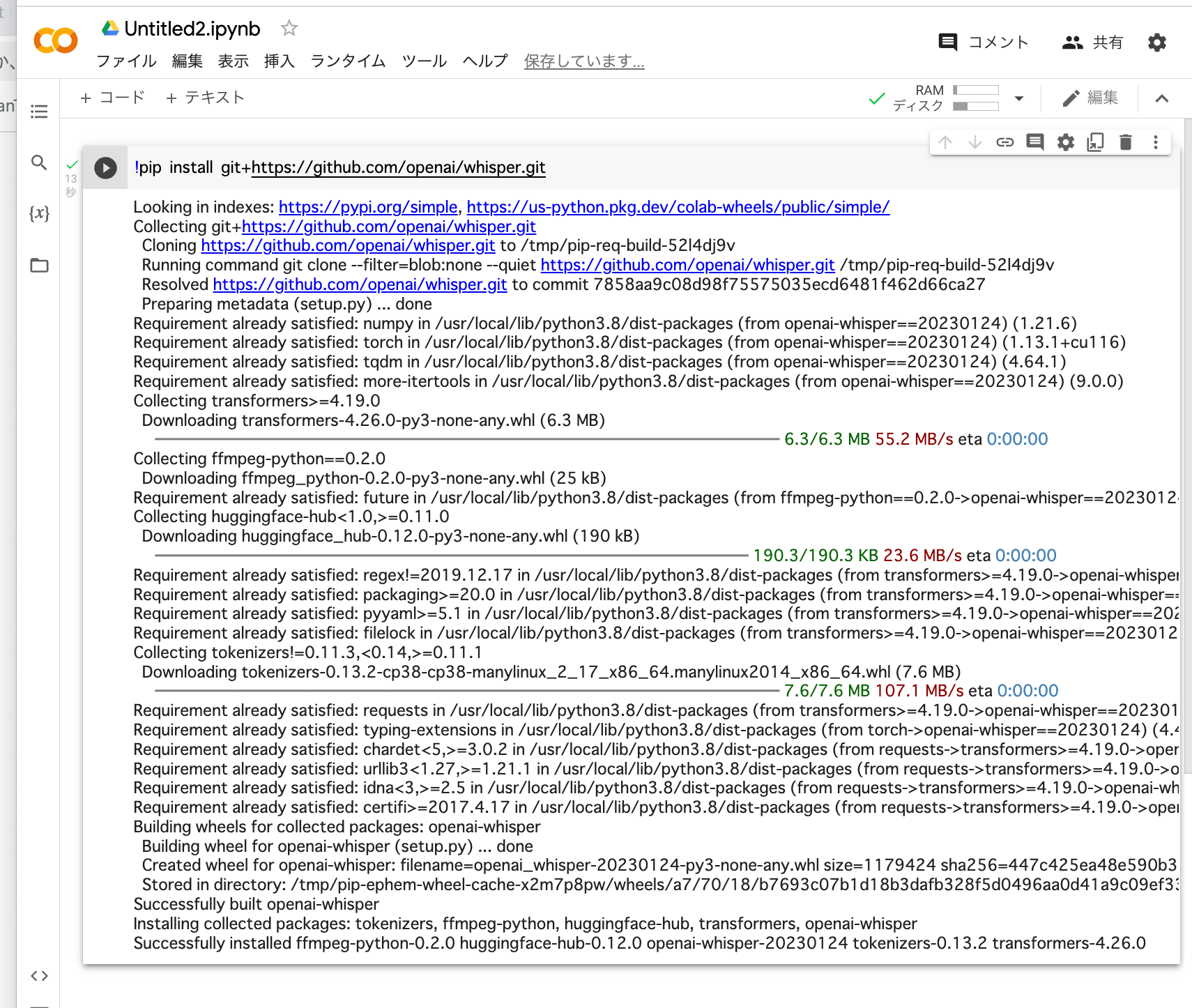
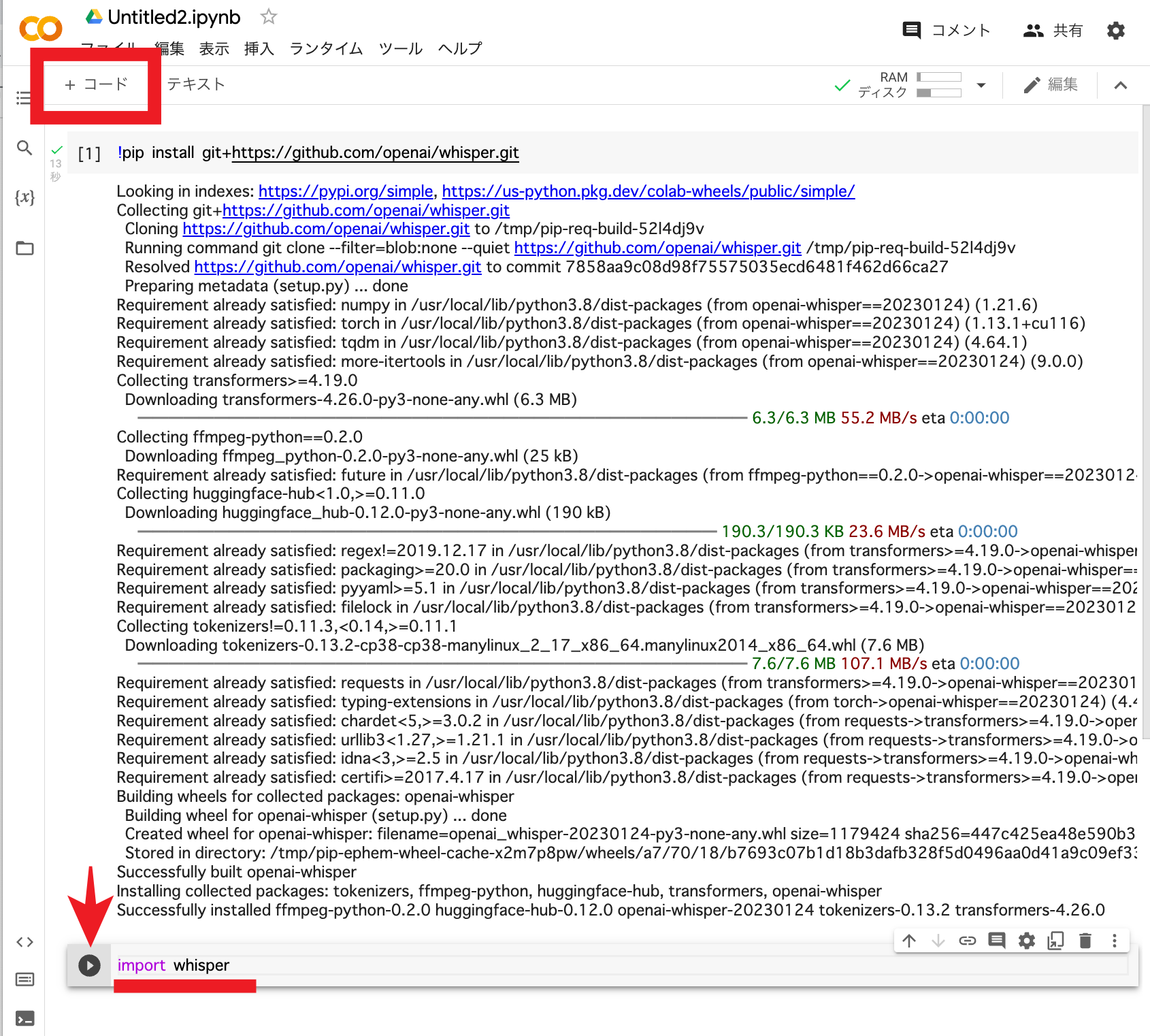
次に「+コード」をクリックして次のコード入力を行います。
下のコードをコピペしてく実行ボタンを押してください。
import whisper
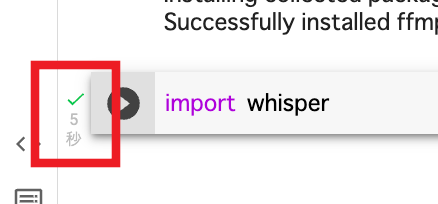
5秒ほど経つとチェックマーグがついて準備完了です。
次に、上で用意した音声ファイルをアップロードします。
左メニューのフォルダで、「content」フォルダを選んで「アップロード」を選択します。
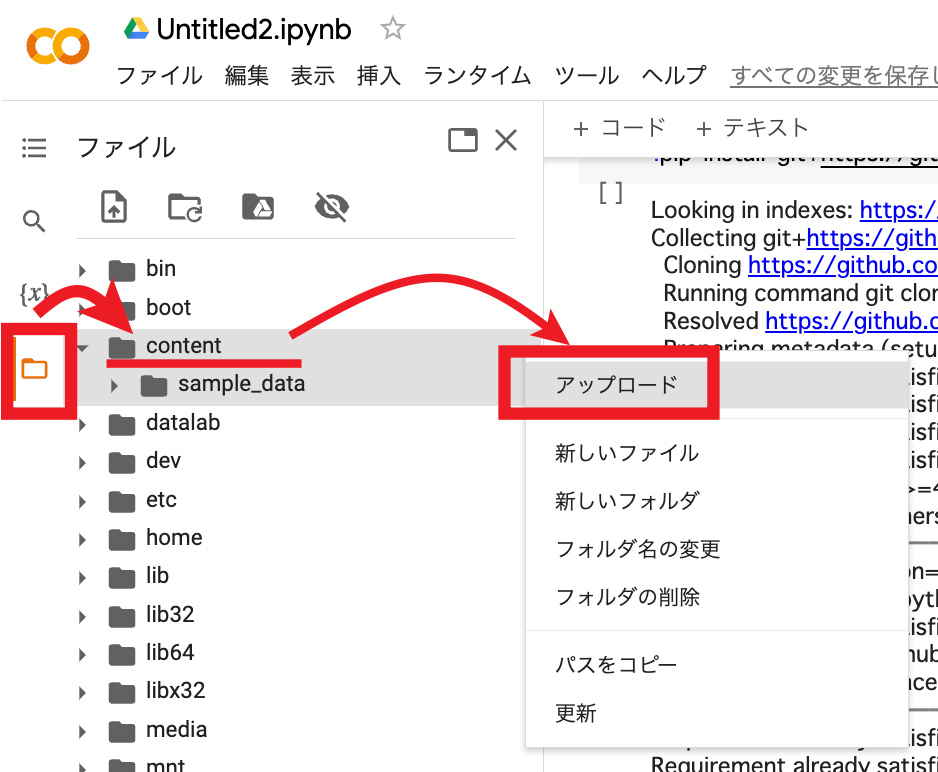
音声ファイルをアップロードすると「content」フォルダに反映されます。
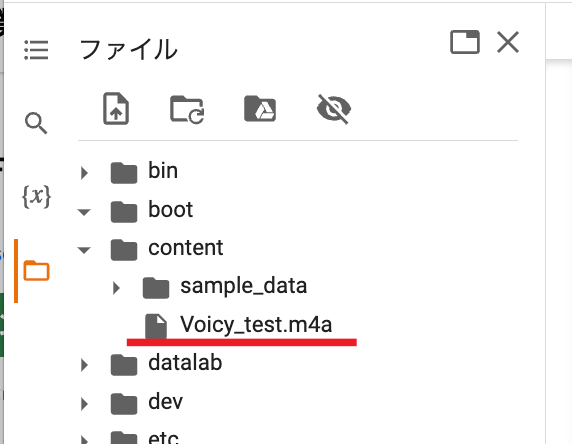
ここから音声ファイルを『Whisper』に文字起こしさせます。
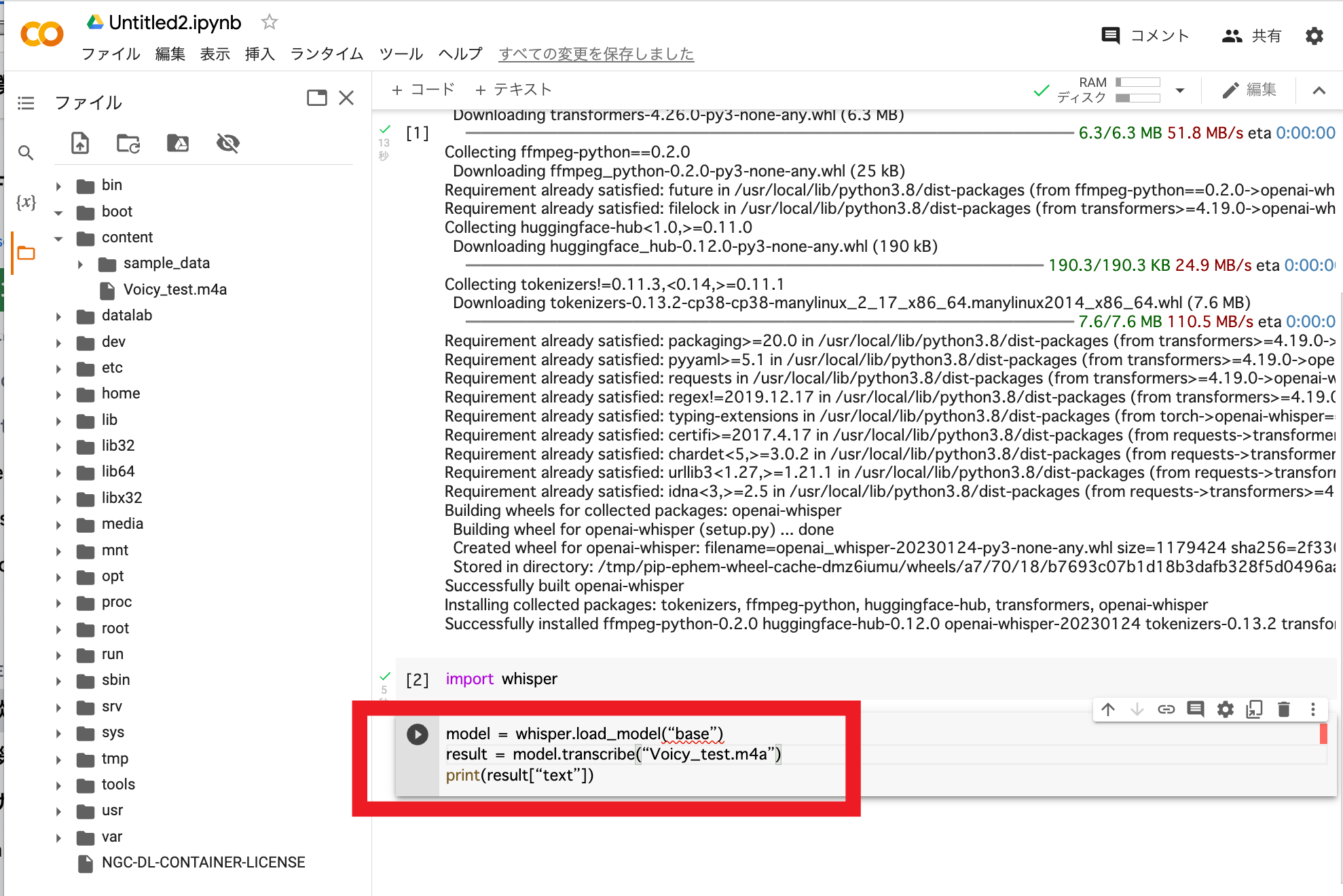
「+コード」をクリックして、以下のコードをコピペしてください。
「base」は5段階ある『Whisper』の文字起こし精度になります。
「Voicy_test.m4a」は文字起こししたい音声データです。
しばらくすると、文字が起こされて表示されます。
1行に表示されてみにくいので、コピーしてGoogleドキュメントなどにペーストして確認してみてください。
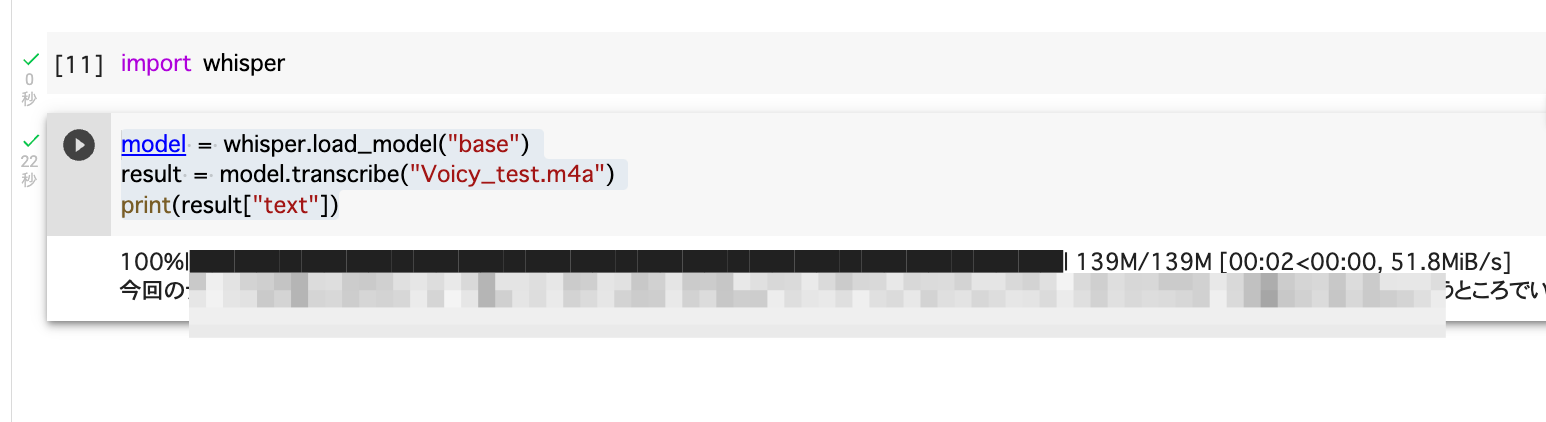
ちなみに、文字起こし精度を一番上の「large」にしてみると、かなりの容量を消費しましたが、音声認識の精度は格段に上がりましたよ。






